
A process in which data is labeled so that AI & ML models can interpret various parameters from data like images, texts, videos, and more is called data annotation. It enables AI & ML models to easily distinguish and group various types of data like images, videos, documents, audio, and more.
When AI & ML modules are in the development phase, they are fed with huge volumes of AI training data so that they can make better decisions when it comes to the identification of objects. We are an AI training data Company that provides datasets for training such models so that they can produce accurate results. For more information, log on to www.dataannotation.it.com.
In this blog, let us discuss different types of data annotation and the generalized process that goes behind it. Keep reading, and keep learning!
Types of Data Annotation
- Image Annotation

Image annotation is commonly used in systems that involve face recognition, computer vision, and more. During the training process, AI experts add captions, identifiers, and keywords to their images which makes it easy for the algorithms to understand these parameters.
Image Classification: It involves classification or assigning labels to images based on their content. It is used to train AI models that aim to recognize and categorize images automatically.
Object Recognition/Detection: In this process, specific objects are identified within an image. With the help of this feature, AI models can highlight objects in images, videos, and even in the real world.
Segmentation: This process involves the division of images into multiple segments each of which corresponds to a specific area of interest. AI models that analyze images at the pixel level use this type of annotation.
- Text Annotation
Most businesses today are dependent on data in the form of text for generating unique insights and information. This text can be anything from healthcare data to customer feedback for a mobile application. Text-based data, however, comes with a lot of semantics.
Text annotation is a tedious process for machines as they cannot understand emotions like sarcasm, humor, grief, and more. For this, some advanced and precise annotation techniques are used in the industry. Some of them are semantic annotation, sentiment annotation, intent annotation, and more.
- Video Annotation
A video is a compilation of images that create an idea of objects being in motion. Video annotation involves the addition of key points, polygons, bounding boxes, and more to annotate multiple objects in individual frames.
These frames are stitched together so that the AI models can learn about the movement, patterns, and behaviors of the objects in the video. With the help of video annotation, concepts like motion blur, localization, and more can be introduced in various systems.
- Audio Annotation
Annotation of audio data is more difficult than annotating image data. This is because audio files include a variety of factors like languages, mood, dialects, emotions, intentions, speakers, and more. Efficient audio annotation algorithms can identify all these parameters. They identify and tag these parameters with the help of timestamping, audio labeling, and similar techniques. Background noises, sound of breaths, and silences also interfere with the audio data annotation process. However, if a system is trained on quality data sets sourced from trusted sources like us, then it can easily and efficiently annotate audio data.
- Entity Annotation
It is a process in which unstructured sentences are tweaked to be made more meaningful. Moreover, its primary purpose is to bring them to a format that is understandable by the machines. For this, entity linking and named entity recognition are involved.
Process Behind Data Labeling & Annotation
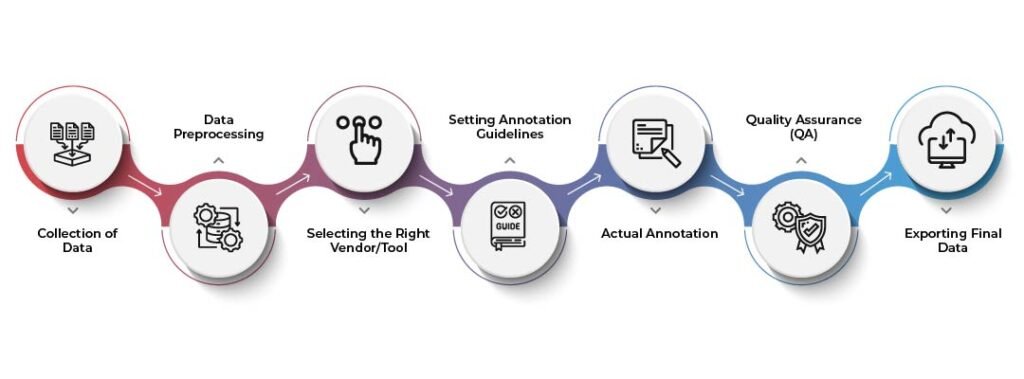
The following is a generalized procedure that goes behind data labeling and annotation:
- Collection of Data: This is the first and foremost step that involves gathering relevant data like images, audio recordings, videos, and more in a centralized location. It makes the accessing of data easy and hassle-free.
- Data Preprocessing: Preprocessing is done to standardize and enhance the collected data. Images are deskewed, text is formatted, and video content is transcribed. This step ensures that data is ready for annotation.
- Selecting the Right Vendor/Tool: This is by far the most important step. A proper data annotation tool or vendor should be chosen depending on the requirements of your project. Based on the requirements of your project, choose an appropriate tool or vendor to annotate your data. We are a great AI training marketplace that can provide you with quality datasets for training your AI & ML models.
- Setting Annotation Guidelines: Annotation guidelines should be established so that accuracy and consistency are maintained throughout the process of data annotation.
- Actual Annotation: Using a human or software annotation system, tag and label the data according to the established guidelines.
- Quality Assurance (QA): Quality assurance needs to be done to have a review of the annotated data. This will ensure accuracy and consistency in the results of data annotation. You may even look to use blind annotation to verify the quality of your results.
- Exporting Final Data: Once the process of data annotation is completed, the data should be exported in the required format.
Depending on the size, complexity, and resources available, the whole data annotation process may take several weeks.
How Can We Assist You?
So, that was a detailed guide to the process of data annotation along with its types. Data annotation is directly used in the development of machine learning models. These models are essential for advancements in the AI space. Data that is well annotated ensures that these models can learn accurately. This ultimately leads to better and more reliable AI applications in various industries.
If you are just starting with the process of data annotation, look no further than us. We have a team of domain experts who will supervise every detail, from data collection to annotation and review.
Further, we have an internal QC team that ensures to fix the flaws discovered during the data improvement process. We provide you with a perfect AI/ML Model within the promised time frame. At our company, we strictly adhere to ISO-27001, SOC II, GDPR & HIPPA standards.
FAQs
Ans: – A process in which data is labeled so that AI & ML models can interpret various parameters from data like images, texts, videos, and more is called data annotation.
Ans: – The annotation of images assists AI algorithms in understanding and processing visual information. It includes techniques like image classification, object recognition/detection, and segmentation.
Ans: – By annotating texts, data can be made understandable for machines. Techniques like semantic annotation, sentiment annotation, and intent annotation are used while doing text annotation.
Ans: – It is the process in which audio data is labeled. This is done so that AI models can recognize various parameters from the data like emotions, speakers, mood, dialects, and more. It includes timestamping, audio labeling, and handling background noises.
Ans: – We provide high-quality datasets for data annotation purposes. We have domain experts for supervision, and an internal QC team for quality assurance, and adhere to ISO-27001, SOC II, GDPR & HIPPA standards, ensuring reliable and efficient AI/ML model training.